- AutorBeiträge
- Oktober 31, 2017 um 19:11 Uhr #20806
 TobiasAdministrator
TobiasAdministratorIm Endeffekt wäre ein Ergebnis ähnlich wie bBoxWeight wünschenswert – also gruppiert in prominence (oder was auch immer) = high/medium/low etc., das würde sich dann umsetzen lassen., die genauen Werte sind eh nicht praktikabel. Wobei high dann zwischen 40.000km und 10km liegen würde, im Endeffekt ist wirklich nur die Unterscheidung für den Nahbereich wichtig.
Ein Problem seh ich auch, dass sich manche peaks in OSM auch ändern – auch die IDs, wenn mal gelöscht/verschoben etc. wird. Daher müsste das regelmäßig aktualisiert werden.Aber solange wir nicht jemand haben, der das wirklich angehen kann, sind das nur Gedankenspiele.
Developer of Elevate mapstyle
Oktober 31, 2017 um 19:34 Uhr #20808mbe57
ModeratorFalls ich den Algorithmus für Fall 1 bekomme, denke ich, dass ich den Rest darum herum bauen kann. Mit dem Kachel- und Nachbarschaftsansatz wird in der Tat nicht der Mount Everest mit dem Montblanc verglichen.
Wenn der Gesamtprozess steht, kann der jeden Monat ablaufen und damit Änderungen passend zu Christians Produktionszyklus laufen.1 Teilnehmer(n) gefällt dieser Beitrag
Oktober 31, 2017 um 19:36 Uhr #20810ModeratorPS: das Framework habe ich bereits durch meinen Ansatz für die Auswahl der darzustellenden Orte in den Übersichtskarten. Kriterien und Abgrenzungen sind natürlich etwas anders.
Oktober 31, 2017 um 19:47 Uhr #20812TobiasAdministratorKlingt gut, ich hoffe, es klappt.
Wir natürlich wieder etwas sein, was mit neueren Mapsforge Versionen gut funktioniert und mit der Locus eigenen Engine nicht. Wobei man wenigstens nach Zoom Level unterscheiden könnte, und die entsprechend früher einblenden (ähnlich der bBoxWeight polynodes).Developer of Elevate mapstyle
Oktober 31, 2017 um 20:38 Uhr #20814ModeratorKennt jemand MaxBe persönlich, oder zumindest besser als ich (nämlich gar nicht) ?
November 3, 2017 um 16:29 Uhr #20849MaxBe
TeilnehmerKennt jemand MaxBe persönlich
Ja, ich 😉 und danke für die Blumen….
Es ist so wie Christian sagt: Es passt nur für kleine Regionen. Der Algorithmus ist einfach:
Variante 1: http://geo.dianacht.de/tests/peak_v1.php.txt
Variante 1 und danach 2: http://geo.dianacht.de/tests/copypeaks.php.txt
(unkommentiert, aber ich erklärs gern, wenn die eine oder andere Zeile wirr aussieht…)Das hilft aber nix, weil der funktioniert nur mit einer postgresql-Datenbank mit OSM-Daten. Das zweite Verfahren braucht sogar zusätzlich eine Datenbank mit Höhendaten und spätestens da werden die Voraussetzungen doch sehr exotisch….
Ich denke, für die Variante 2 muss man irgendwas mit der libgdal und einen GeoTiff mit Höhendaten machen. Variante 1 alleine lohnt meines Erachtens nicht, weil zu viele kleine Gipfel fälschlich als zu dominant dargestellt werden. Ab und zu denke ich auch darüber nach, wenns regnet. Ich hätte das nämlich gerne in der OpenTopoMap eingebaut. Aber ich warte noch auf einen plötzlichen Einfall 😉
Grüße
MaxPS: Das ist auch erst die halbe Miete… Dass wichtige Gipfel zuerst dargestellt werden ist klar. Das Problem ist das Zusammenspiel mit anderen POIs. Was ist wichtiger: ein Gipfel mit 40km Dominanz oder erst eine Stadt mit 40k Einwohner…?
Edit: Falls einer nachbauen will: Weil ich ja mit „ele=*“ rechnen muss, putze ich dieses Tag beim Update immer recht gründlich. Leerzeichen weg, vorangestellte „c.a.“ und nachgestellte „Meter“ raus, Kommas in Punkt umwandeln… Und falls gar keine Zahl mehr übrig ist nach dem Putzen, greife ich auf „srtmele“ zurück. Da steht die Höhe aus den Höhrendaten drin, die aus der anderen Datenbank kommt.
1 Teilnehmer(n) gefällt dieser Beitrag
November 3, 2017 um 20:21 Uhr #20854ModeratorDanke, Max, für Deine Informationen und Deine Einschätzung.
Wenn man auf der Basis von Dominanz im geografischen Sinne arbeiten will, wird es in der Tat blutig. Aber: braucht man das denn wirklich ?Das ganze Folgende setzt für Locus voraus, dass Menion endlich seine Hausaufgaben macht und Prioritäten, aber zumindest die Funktion „display=always“ für Themes implementiert.
In einem gegebenen Gebiet eines bestimmten Zoom-Levels sind bei gegebener Font-Größe maximal soundsoviel Texte darstellbar. Wenn Städte mit Gipfeln konkurrieren – so what. Dann werden sie eben überlappend dargestellt und sagen dem Benutzer: „In diesem Zoomlevel bekommst Du nicht alle Infos im Detail zu sehen“. Das gilt auch für nahe beieinander liegende Gipfel. Und solange die höchsten x Gipfel auch die wichtigsten sind, kann man m.E. etwas brutaler vorgehen. Mit „x“ muss man etwas spielen, um z.B. Tobias‘ Fall dargestellt zu bekommen; beide dann eben …
Kann diese Vorgehensweise Sinn machen?
D.h. für jedes Zoom-Level z.B. ab 10 sucht man in jeder „Kachel“ (Größe abhängig vom Zoom-Level) wiederum abhängig vom Zoom-Level die N höchsten Gipfel. Die bekommen dann Tags ab welchem ZL sie dargestellt werden sollen. Der Rest ist Sache des Themes, wie Tobias schon vorgeschlagen hat.
Das Ganze lässt sich mit einem awk- oder Python-Script in linearer Zeit berechnen. es braucht nicht einmal eine Entfernungsberechnung.
Wissenschaftlich ist das natürlich nicht, aber eben realisierbar für die 1/2 Mio Peaks in OSM.November 3, 2017 um 21:35 Uhr #20856TobiasAdministratorKann diese Vorgehensweise Sinn machen?
D.h. für jedes Zoom-Level z.B. ab 10 sucht man in jeder „Kachel“ (Größe abhängig vom Zoom-Level) wiederum abhängig vom Zoom-Level die N höchsten Gipfel. Die bekommen dann Tags ab welchem ZL sie dargestellt werden sollen.Für die Darstellung im Theme wäre es gut, das nicht für jeden ZL zu berechnen, sondern nur einen Wert pro Gipfel zu haben. Die mit den höheren Werten werden dann schon früher dargestellt, aber eben abhängig von einem vorher für ein Gebiet berechneter Wert.
Von den Kachelgrößen auszugehen ist etwas schwierig, da die ja flexibel, abhängig von der Pixeldichte des Gerätes, sind (wenn mapsforge korrekt implentiert ist). Aber es macht schon Sinn, sich da auf irgendeine gut berechenbare Größe festzulegen. Das Problem sind bei Kacheln wieder die Kachelränder, wenn ein Gipfel am Rand für die Kachel dominant ist, heißt das nicht, dass der neben ihm auf der nächsten Kachel niedriger ist.Developer of Elevate mapstyle
November 3, 2017 um 22:44 Uhr #20858TeilnehmerAber: braucht man das denn wirklich ?
Gute Frage, ich glaube ja…
Nur nach Höhe innerhalb einer Kachel zu schauen wird nicht langen. Zum einen passt die Kachel ja nie, zum anderen haben wir einfach zu viele Gipfel. Das mag auch ein alpenländisches Problem sein, woanders ist man zurückhaltender damit, einen Zacken im Grat „Gipfel“ zu nennen und ihm sogar einen Namen zu geben.
Zum Beispiel: Rund ums Karwendeltal dürften Birkkarspitze im Süden und östliche Karwendelspitze im Norden die „wichtigsten“ Berge sein, jedenfalls die im Panorama prägnantesten. Nach Entfernung gerechnet stimmt das auch. Nach Höhe käme die östliche Karwendelspitze ziemlich weit hinten, weil in der Kette östlich und westlich der Birkkarspitze jede Menge andere Gipfel liegen, die zwar nicht dominant (weil nahe an der Birkkarspitze), aber hoch sind (weil nahe am höchsten Gipfel der Gegend).
Bei Bergen wie dem Hohen Nock würde es funktionieren. Der steht recht isoliert. Ausser die Kachel erwischt mit einem Eck noch das Tote Gebirge, da stehen dutzende Gipfel die den Hohen Nock übertrumpfen und die keiner kennt (glaube ich, kenn mich da nicht aus).
Aber wie gesagt, so richtig tolle Ideen jenseits von „wir rechnen das durch und wenns Stunden dauert“ hatte ich auch noch nicht, vielleicht täusche ich mich auch 😉
Grüße
MaxNovember 5, 2017 um 11:21 Uhr #20868 ChristianKAdministrator
ChristianKAdministratorHallo Max,
Danke das Du dir die Mühe gemacht hast dich hier anzumelden!
Ich schätze zur Zeit sind hier einige Leute am Nachdenken wie eine Lösung aussehen könnte.So einfach wie in Schottland wo die Gipfel von Haus aus in Munroes/Corbets etc. eingeteilt sind geht’s im Rest der Welt leider nicht 😉
Schau mer mal…
LG, Christian
November 5, 2017 um 16:22 Uhr #20870TeilnehmerHi Christian.
ja gern, ich hab mit OAM schon viele dominante und undominante Gipfel gefunden 😉Ich hab auch mal bisschen nachgedacht. Wenn man sich auf „Dominanz ist der Abstand zum nächsthöheren Gipfel“ beschränkt, könnte man das als gelegentliche Aufgabe laufen lassen. Die Berechnung für die Alpen dauern ein paar Minuten, die Welt kann auch 2 Stunden dauern. Das ist nicht das, was ich will (ich will echte Dominanzen *aufstampf*), aber vielleicht ein Anfang.
Nur so als Entwurf, bevor ich 2 oder 3 Wochen nix dran mache: Dieses Programm erzeugt aus diesen Eingangsdaten diese Ausgangsdaten. Diese CSV-Dateien wären ungefähr das Ausgabeformat, das auch das Endprodukt hätte, falls es läuft.
Das ist in C geschrieben, weil ich da die Bibliotheken fürs Lesen der Höhendaten habe. Gipfel, die keine lesbare Höhe haben (weil nicht vorhanden oder mit Texten garniert oder Tausendertrennpünktchen oder Masseinheiten) bekommen eine Höhe aus den Höhendaten zugewiesen.
Die maximale Dominanz sind 100km, weil die Erde ist eine Scheibe. Ich habe nämlich keine Lust, die Entfernungsberechnung zwischen Mont Blanc und dem Kaukasus korrekt auf der Kugel über einen Bogen nach Norden zu rechnen. Für ein paar hundert km sollte das aber auch mit einfacher Berechnung passen und zum Rendern ist irgendwie ja alles was 100km Dominanz hat schon sehr wichtig.
Über den 180. Längengrad hinaus wird auch nicht gerechnet: Alaskas Gipfel liegen liegt ganz weit westlich von sibirischen Bergen.
Die minimale Entfernung ist 100m, weil wenn ich mal echte Höhendaten verwende, empfiehlt es sich, erst mal ein Stück vom Gipfel wegzugehen, bevor man den nächstgelegenen Berg sucht.
Sind sicher auch noch Fehler drin, ich hab mich nur mal zum Testen in einem kleinen Gebirge von Gipfel zu Gipfel gehangelt und da stimmte es…
Die Daten für den Test kommen aus einer OverPass-Abfrage. Irgendwas mit GIS-Datenbank wäre sicher performanter, weil dort die Gipfel schon indiziert sind und man gezielt die Gipfel im 100km Umkreis raussuchen kann. Für den Test wird jeder Gipfel mit jedem anderen verglichen, obwohl die Mehrzahl davon viel zu weit weg liegt. Dafür hat man mit OverPass natürlich weniger Pflegeaufwand…
Grüße
MaxNovember 5, 2017 um 17:32 Uhr #20872ModeratorWOW!!
November 9, 2017 um 17:24 Uhr #20920TeilnehmerIch hab noch ein bisschen gebastelt, das da oben war äh.. sehr unperformant: Programm, Eingangsdaten (csv mit id;lon;lat;ele), Ausgangsdaten (csv mit id;lon;lat;dominanz in Meter). Die sind alle derzeitigen natural=peak und natural=volcano.
Da wird jetzt die „echte“ Dominanz berechnet, (maximal 100km), basierend auf Höhendaten von viewfinderpanoramas.org. Die Erlaubnis, Dominanzen aus diesen Daten zu veröffentlichen hab ich mir schon mal besorgt.
Schaut mal, ob Ihr was damit anfangen könnt. Falls ja, könnte ich das auch als gelegentliche Liste anbieten, die Berechnung dauert eine gute Stunde, zu verkehrsarmen Zeiten könnts auch schneller gehn. Regelmässige Updates der Liste und Dokumentation mit mehrfarbigen Abbildungen gibts im Winter 😉
Die Auswertung auf meiner Karte verwendet übrigens die Einteilung 5000=wichtig, 1200=mittelwichtig, <1200 unwichtiger Berg. Die ist aber nach intensivem Betrachten der bayerischen Alpen entstanden, könnte sein, dass andere Gegenden andere Grenzen brauchen.
Für den Hohen Nock (dominanz=13890 bis er südwestlich aufs Tote Gebirge stösst) und seine Nachbarn Seekopf (dom=425) und Gamsplan (dom=1207) könnts aber passen. Extreme Fälle wie den Pinneberg (61m hoch, aber 92km Dominanz) gibts natürlich auch, aber vielleicht finden Helgoländer ihren Inselgipfel tatsächlich sehr bedeutsam…
Grüße
MaxNovember 9, 2017 um 20:26 Uhr #20924TeilnehmerNachtrag: Weil ich immer Bilder brauche, um mir was vorzustellen: Hier die Berge des Sengsengebirges. Die Striche gehen immer vom Gipfel zum nächsthöheren Punkt am Gegenhang. Die Beschriftung der Striche ist die Dominanz. (den Fehler beim Zwielauf Bildmitte oben hab ich gefunden… der Rotgsol läge ja näher…)
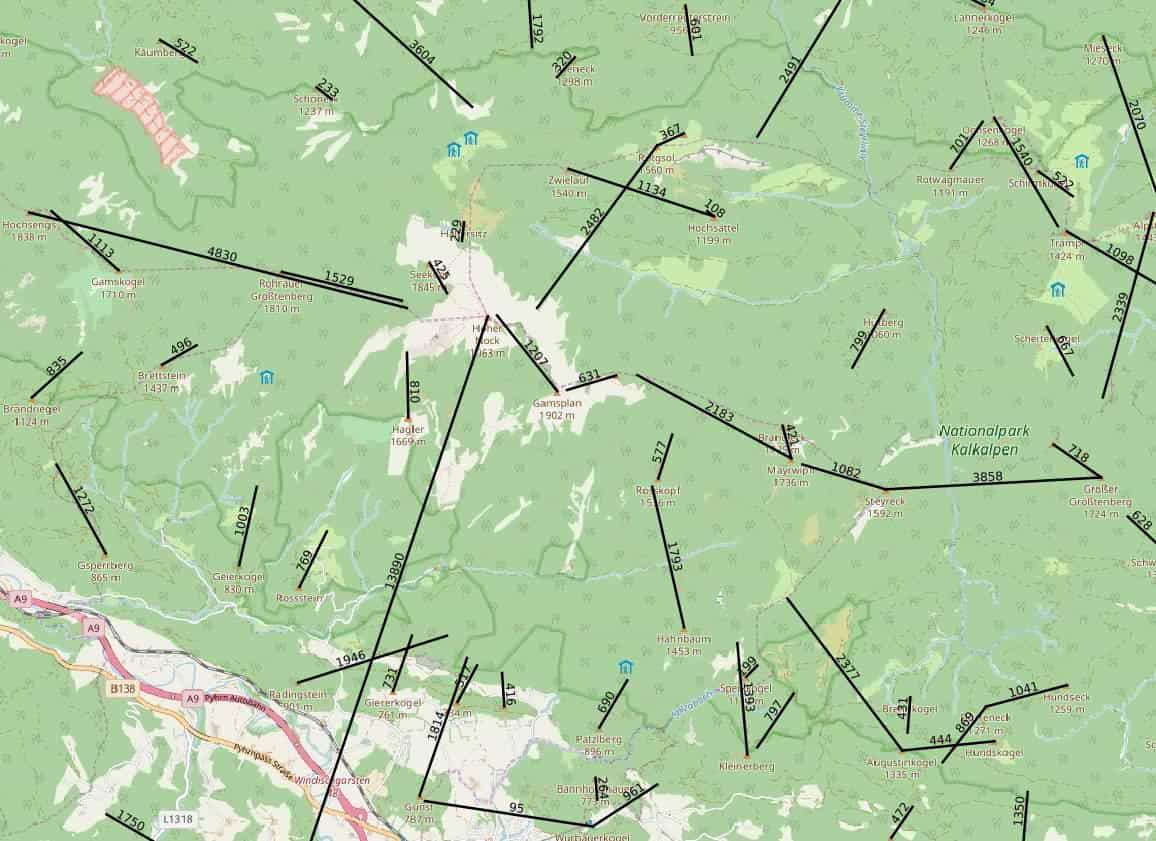
3 users thanked author for this post.
November 9, 2017 um 21:59 Uhr #20930TobiasAdministratorVielen Dank für Deine Mühen, das sieht ja alles ganz hervorragend aus. Auch die Erfahrungswerte für die Einteilung sind schon mal hilfreich.
@ChristianK – was meinst Du, kannst Du die Ergebnisse so verarbeiten? Die Werte müssen natürlich noch gruppiert werden, ggf. noch etwas feiner zum Testen.Developer of Elevate mapstyle
- AutorBeiträge
- Sie müssen angemeldet sein, um zu diesem Thema eine Antwort verfassen zu können.